Explaining the behavior of trained neural networks remains a compelling puzzle, especially as these models grow in size and sophistication. Like other scientific challenges throughout history, reverse-engineering how artificial intelligence systems work requires a substantial amount of experimentation: making hypotheses, intervening on behavior, and even dissecting large networks to examine individual neurons.
Facilitating this timely endeavor, researchers from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) have developed a novel approach that uses AI models to conduct experiments on other systems and explain their behavior. Their method uses agents built from pretrained language models to produce intuitive explanations of computations inside trained networks.
Central to this strategy is the “automated interpretability agent” (AIA), designed to mimic a scientist’s experimental processes. Interpretability agents plan and perform tests on other computational systems, which can range in scale from individual neurons to entire models, in order to produce explanations of these systems in a variety of forms: language descriptions of what a system does and where it fails, and code that reproduces the system’s behavior.
Unlike existing interpretability procedures that passively classify or summarize examples, the AIA actively participates in hypothesis formation, experimental testing, and iterative learning, thereby refining its understanding of other systems in real time.
Complementing the AIA method is the new “function interpretation and description” (FIND) benchmark, a test bed of functions resembling computations inside trained networks, and accompanying descriptions of their behavior.
One key challenge in evaluating the quality of descriptions of real-world network components is that descriptions are only as good as their explanatory power: Researchers don’t have access to ground-truth labels of units or descriptions of learned computations. FIND addresses this long-standing issue in the field by providing a reliable standard for evaluating interpretability procedures: explanations of functions (e.g., produced by an AIA) can be evaluated against function descriptions in the benchmark.
For example, FIND contains synthetic neurons designed to mimic the behavior of real neurons inside language models, some of which are selective for individual concepts such as “ground transportation.” AIAs are given black-box access to synthetic neurons and design inputs (such as “tree,” “happiness,” and “car”) to test a neuron’s response. After noticing that a synthetic neuron produces higher response values for “car” than other inputs, an AIA might design more fine-grained tests to distinguish the neuron’s selectivity for cars from other forms of transportation, such as planes and boats.
When the AIA produces a description such as “this neuron is selective for road transportation, and not air or sea travel,” this description is evaluated against the ground-truth description of the synthetic neuron (“selective for ground transportation”) in FIND. The benchmark can then be used to compare the capabilities of AIAs to other methods in the literature.
Sarah Schwettmann, Ph.D., co-lead author of a paper on the new work and a research scientist at CSAIL, emphasizes the advantages of this approach. The paper is available on the arXiv preprint server.
“The AIAs’ capacity for autonomous hypothesis generation and testing may be able to surface behaviors that would otherwise be difficult for scientists to detect. It’s remarkable that language models, when equipped with tools for probing other systems, are capable of this type of experimental design,” says Schwettmann. “Clean, simple benchmarks with ground-truth answers have been a major driver of more general capabilities in language models, and we hope that FIND can play a similar role in interpretability research.”
Automating interpretability
Large language models are still holding their status as the in-demand celebrities of the tech world. The recent advancements in LLMs have highlighted their ability to perform complex reasoning tasks across diverse domains. The team at CSAIL recognized that given these capabilities, language models may be able to serve as backbones of generalized agents for automated interpretability.
“Interpretability has historically been a very multifaceted field,” says Schwettmann. “There is no one-size-fits-all approach; most procedures are very specific to individual questions we might have about a system, and to individual modalities like vision or language. Existing approaches to labeling individual neurons inside vision models have required training specialized models on human data, where these models perform only this single task.
“Interpretability agents built from language models could provide a general interface for explaining other systems—synthesizing results across experiments, integrating over different modalities, even discovering new experimental techniques at a very fundamental level.”
As we enter a regime where the models doing the explaining are black boxes themselves, external evaluations of interpretability methods are becoming increasingly vital. The team’s new benchmark addresses this need with a suite of functions, with known structure, that are modeled after behaviors observed in the wild. The functions inside FIND span a diversity of domains, from mathematical reasoning to symbolic operations on strings to synthetic neurons built from word-level tasks.
The dataset of interactive functions is procedurally constructed; real-world complexity is introduced to simple functions by adding noise, composing functions, and simulating biases. This allows for comparison of interpretability methods in a setting that translates to real-world performance.
In addition to the dataset of functions, the researchers introduced an innovative evaluation protocol to assess the effectiveness of AIAs and existing automated interpretability methods. This protocol involves two approaches. For tasks that require replicating the function in code, the evaluation directly compares the AI-generated estimations and the original, ground-truth functions. The evaluation becomes more intricate for tasks involving natural language descriptions of functions.
In these cases, accurately gauging the quality of these descriptions requires an automated understanding of their semantic content. To tackle this challenge, the researchers developed a specialized “third-party” language model. This model is specifically trained to evaluate the accuracy and coherence of the natural language descriptions provided by the AI systems, and compares it to the ground-truth function behavior.
FIND enables evaluation revealing that we are still far from fully automating interpretability; although AIAs outperform existing interpretability approaches, they still fail to accurately describe almost half of the functions in the benchmark.
Tamar Rott Shaham, co-lead author of the study and a postdoc in CSAIL, notes that “while this generation of AIAs is effective in describing high-level functionality, they still often overlook finer-grained details, particularly in function subdomains with noise or irregular behavior.
“This likely stems from insufficient sampling in these areas. One issue is that the AIAs’ effectiveness may be hampered by their initial exploratory data. To counter this, we tried guiding the AIAs’ exploration by initializing their search with specific, relevant inputs, which significantly enhanced interpretation accuracy.” This approach combines new AIA methods with previous techniques using pre-computed examples for initiating the interpretation process.
The researchers are also developing a toolkit to augment the AIAs’ ability to conduct more precise experiments on neural networks, both in black-box and white-box settings. This toolkit aims to equip AIAs with better tools for selecting inputs and refining hypothesis-testing capabilities for more nuanced and accurate neural network analysis.
The team is also tackling practical challenges in AI interpretability, focusing on determining the right questions to ask when analyzing models in real-world scenarios. Their goal is to develop automated interpretability procedures that could eventually help people audit systems—e.g., for autonomous driving or face recognition—to diagnose potential failure modes, hidden biases, or surprising behaviors before deployment.
Watching the watchers
The team envisions one day developing nearly autonomous AIAs that can audit other systems, with human scientists providing oversight and guidance. Advanced AIAs could develop new kinds of experiments and questions, potentially beyond human scientists’ initial considerations.
The focus is on expanding AI interpretability to include more complex behaviors, such as entire neural circuits or subnetworks, and predicting inputs that might lead to undesired behaviors. This development represents a significant step forward in AI research, aiming to make AI systems more understandable and reliable.
“A good benchmark is a power tool for tackling difficult challenges,” says Martin Wattenberg, computer science professor at Harvard University who was not involved in the study. “It’s wonderful to see this sophisticated benchmark for interpretability, one of the most important challenges in machine learning today. I’m particularly impressed with the automated interpretability agent the authors created. It’s a kind of interpretability jiu-jitsu, turning AI back on itself in order to help human understanding.”
Schwettmann, Rott Shaham, and their colleagues presented their work at NeurIPS 2023 in December. Additional MIT co-authors, all affiliates of the CSAIL and the Department of Electrical Engineering and Computer Science (EECS), include graduate student Joanna Materzynska, undergraduate student Neil Chowdhury, Shuang Li, Ph.D., Assistant Professor Jacob Andreas, and Professor Antonio Torralba. Northeastern University Assistant Professor David Bau is an additional co-author.
More information: Sarah Schwettmann et al, FIND: A Function Description Benchmark for Evaluating Interpretability Methods, arXiv (2023). DOI: 10.48550/arxiv.2309.03886
News

Studies detail high rates of long COVID among healthcare, dental workers
Researchers have estimated approximately 8% of Americas have ever experienced long COVID, or lasting symptoms, following an acute COVID-19 infection. Now two recent international studies suggest that the percentage is much higher among healthcare workers [...]
Melting Arctic Ice May Unleash Ancient Deadly Diseases, Scientists Warn
Melting Arctic ice increases human and animal interactions, raising the risk of infectious disease spread. Researchers urge early intervention and surveillance. Climate change is opening new pathways for the spread of infectious diseases such [...]
Scientists May Have Found a Secret Weapon To Stop Pancreatic Cancer Before It Starts
Researchers at Cold Spring Harbor Laboratory have found that blocking the FGFR2 and EGFR genes can stop early-stage pancreatic cancer from progressing, offering a promising path toward prevention. Pancreatic cancer is expected to become [...]
Breakthrough Drug Restores Vision: Researchers Successfully Reverse Retinal Damage
Blocking the PROX1 protein allowed KAIST researchers to regenerate damaged retinas and restore vision in mice. Vision is one of the most important human senses, yet more than 300 million people around the world are at [...]

Differentiating cancerous and healthy cells through motion analysis
Researchers from Tokyo Metropolitan University have found that the motion of unlabeled cells can be used to tell whether they are cancerous or healthy. They observed malignant fibrosarcoma cells and [...]
This Tiny Cellular Gate Could Be the Key to Curing Cancer – And Regrowing Hair
After more than five decades of mystery, scientists have finally unveiled the detailed structure and function of a long-theorized molecular machine in our mitochondria — the mitochondrial pyruvate carrier. This microscopic gatekeeper controls how [...]
Unlocking Vision’s Secrets: Researchers Reveal 3D Structure of Key Eye Protein
Researchers have uncovered the 3D structure of RBP3, a key protein in vision, revealing how it transports retinoids and fatty acids and how its dysfunction may lead to retinal diseases. Proteins play a critical [...]

5 Key Facts About Nanoplastics and How They Affect the Human Body
Nanoplastics are typically defined as plastic particles smaller than 1000 nanometers. These particles are increasingly being detected in human tissues: they can bypass biological barriers, accumulate in organs, and may influence health in ways [...]
Measles Is Back: Doctors Warn of Dangerous Surge Across the U.S.
Parents are encouraged to contact their pediatrician if their child has been exposed to measles or is showing symptoms. Pediatric infectious disease experts are emphasizing the critical importance of measles vaccination, as the highly [...]

AI at the Speed of Light: How Silicon Photonics Are Reinventing Hardware
A cutting-edge AI acceleration platform powered by light rather than electricity could revolutionize how AI is trained and deployed. Using photonic integrated circuits made from advanced III-V semiconductors, researchers have developed a system that vastly [...]
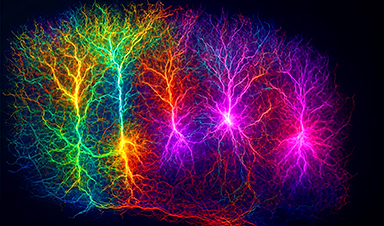
A Grain of Brain, 523 Million Synapses, Most Complicated Neuroscience Experiment Ever Attempted
A team of over 150 scientists has achieved what once seemed impossible: a complete wiring and activity map of a tiny section of a mammalian brain. This feat, part of the MICrONS Project, rivals [...]
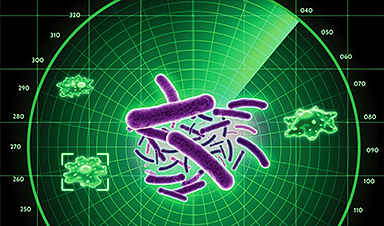
The Secret “Radar” Bacteria Use To Outsmart Their Enemies
A chemical radar allows bacteria to sense and eliminate predators. Investigating how microorganisms communicate deepens our understanding of the complex ecological interactions that shape our environment is an area of key focus for the [...]

Psychologists explore ethical issues associated with human-AI relationships
It's becoming increasingly commonplace for people to develop intimate, long-term relationships with artificial intelligence (AI) technologies. At their extreme, people have "married" their AI companions in non-legally binding ceremonies, and at least two people [...]
When You Lose Weight, Where Does It Actually Go?
Most health professionals lack a clear understanding of how body fat is lost, often subscribing to misconceptions like fat converting to energy or muscle. The truth is, fat is actually broken down into carbon [...]
How Everyday Plastics Quietly Turn Into DNA-Damaging Nanoparticles
The same unique structure that makes plastic so versatile also makes it susceptible to breaking down into harmful micro- and nanoscale particles. The world is saturated with trillions of microscopic and nanoscopic plastic particles, some smaller [...]

AI Outperforms Physicians in Real-World Urgent Care Decisions, Study Finds
The study, conducted at the virtual urgent care clinic Cedars-Sinai Connect in LA, compared recommendations given in about 500 visits of adult patients with relatively common symptoms – respiratory, urinary, eye, vaginal and dental. [...]