While AI models can break down problems into structured steps, new research reveals they still fail at basic arithmetic and fact-checking—raising questions about their true reasoning abilities.
Large Language Models (LLMs) have become indispensable in natural language processing, excelling at tasks such as sentiment analysis, reading comprehension, and answering factual questions. However, their ability to perform complex, multi-step reasoning remains a significant challenge, particularly in question-answering tasks that demand logical inference rather than simple recall. This study, authored by Nick Ferguson, Liane Guillou, Alan Bundy, and Kwabena Nuamah from the University of Edinburgh and Aveni, examines the extent to which LLMs can engage in two distinct forms of reasoning: meta-level and object-level reasoning.
Understanding Meta-Level and Object-Level Reasoning
Meta-level reasoning involves high-level strategic thinking, including problem decomposition and the formulation of intermediate steps necessary to solve a question. Object-level reasoning, in contrast, refers to the execution of these steps, such as performing mathematical calculations, retrieving specific facts, or applying symbolic logic. To evaluate the capabilities of LLMs in these areas, the authors introduce FRANKLIN, a novel dataset that explicitly requires models to engage in both reasoning types. FRANKLIN is inspired by the FRANK system, a symbolic reasoning framework for question answering, and focuses on geopolitical indicators such as population trends, economic metrics, and regional comparisons. Alongside three established multi-step question-answering datasets, FRANKLIN serves as a benchmark for testing the performance of four specific LLM versions: Meta’s Llama 3.1 8B, Microsoft’s Phi 3.5 Mini, Google’s Gemma 2 9B, and OpenAI’s GPT-4o-mini. Through two human annotation studies, the researchers assess whether LLMs can successfully generate reasoned responses and whether prompting them to plan their answers before execution improves their performance.
How LLMs Approach Reasoning Tasks
The study situates its analysis within the broader context of LLM reasoning tasks. As a cognitive function, reasoning encompasses logical deduction, belief revision, and inference-making. Common sense reasoning requires an understanding of everyday concepts and the ability to infer implicit knowledge. Mathematical reasoning demands numerical operations and logical problem-solving, while symbolic reasoning involves rule-based manipulations, such as emulating formal logic or deducing relationships between abstract entities. Multi-step reasoning is particularly significant, as it necessitates the sequential application of inference processes to arrive at a final answer. Despite their advancements, LLMs often struggle with these tasks because they rely on statistical pattern-matching rather than genuine logical deduction.
Existing techniques attempt to improve LLM performance on reasoning tasks. Fine-tuning involves additional training on domain-specific datasets to enhance accuracy in particular tasks while prompting techniques such as Chain-of-Thought (CoT) to introduce explicit reasoning steps into model responses. These approaches have demonstrated improvements, yet doubts remain as to whether LLMs are genuinely reasoning or merely imitating structured thought patterns learned from their training data. The authors propose a more structured classification of LLM reasoning, distinguishing between meta-level and object-level processes. While meta-level reasoning involves planning, selecting relevant knowledge sources, and determining the steps required to solve a problem, object-level reasoning focuses on accurate execution, including factual retrieval, numerical precision, and logical deductions.
FRANKLIN Dataset: A New Challenge for LLMs
To assess these reasoning types, the study introduces the FRANKLIN dataset, inspired by the FRANK system, which employs explicit symbolic reasoning to solve complex questions. FRANKLIN consists of complex questions requiring both meta- and object-level reasoning, particularly in the domain of geopolitical indicators. It includes scenarios requiring future prediction, regional comparisons, historical trends, and projections. Unlike more straightforward fact-retrieval datasets, FRANKLIN forces LLMs to not only determine the correct problem-solving approach but also accurately retrieve and manipulate relevant data. Each question is paired with a detailed explanation outlining the necessary reasoning steps. This dataset poses a significant challenge for LLMs, as it requires them not only to determine the appropriate strategy for answering a question but also to accurately retrieve and manipulate data.
How LLMs Were Evaluated: Two Human Annotation Studies
The evaluation design consists of two human annotation studies. In the first, LLMs were prompted to directly answer questions, allowing assessment of their object-level reasoning abilities. In the second, models were first asked to generate a plan before executing their reasoning steps, testing their meta-level reasoning skills. Participants rated responses based on their coherence, correctness, and the presence of structured reasoning. The study also introduced three key evaluation metrics:
- Answer Failure Rate (AFR) – the percentage of cases where an LLM provided no attempted answer.
- Rational Approach Rate (RAR) – the proportion of responses that outlined a coherent problem-solving approach.
- Plan Creation Rate (PCR) – the percentage of responses that structured their reasoning in a clear, step-by-step manner.
The results reveal a clear divergence in LLM performance between these two reasoning levels.
Key Findings: Meta-Level Strength, Object-Level Weakness
Across all datasets, LLMs consistently demonstrated strong meta-level reasoning. Responses often contained structured, step-by-step explanations that human annotators rated as rational and interpretable. Even for complex questions in FRANKLIN, models exhibited an ability to break down problems into intermediate steps and articulate a plan for solving them. However, while these responses appeared structured, the study raises concerns about whether they represent true reasoning or simply an imitation of learned patterns.
In contrast, LLMs struggled significantly with object-level reasoning. Object-level reasoning failures were frequent, particularly when questions required numerical precision or factual recall. In FRANKLIN, for example, models frequently fabricated numerical data, provided incorrect values, or made basic arithmetic errors. Even when models successfully identified the correct reasoning path, they often failed to follow through with accurate computations or fact retrieval. Error patterns included:
- Fabricating numerical data (e.g., citing non-existent sources).
- Retrieving inaccurate or imprecise information (e.g., rounding values incorrectly).
- Performing incorrect calculations (even for simple arithmetic operations).
A closer analysis of errors highlights the nature of these failures. Some responses contained entirely fabricated data, where models cited non-existent sources or invented statistical figures. Others retrieved information with reduced precision, rounding values or omitting key details necessary for accurate comparisons. In mathematical tasks, models often produce incorrect calculations, even for simple operations. These findings suggest that while LLMs can structure their responses in a way that appears logical, they lack the robust execution skills necessary to reliably generate correct answers in domains requiring object-level reasoning.
Implications for LLM Development
The findings have significant implications for the development of LLMs. While prompting models to engage in meta-level reasoning improves their ability to articulate coherent strategies, it does not address their deficiencies in object-level reasoning. This suggests that future advancements must focus on integrating external symbolic reasoning components, improving factual retrieval mechanisms, and refining numerical processing capabilities. The FRANKLIN dataset serves as a critical benchmark, demonstrating that even models with strong problem-decomposition skills struggle with execution.
Conclusion: The Path Forward for AI Reasoning
In conclusion, the study highlights a critical distinction in the reasoning capabilities of LLMs. While they can effectively plan and structure problem-solving approaches, their ability to execute complex reasoning tasks remains limited. The study’s findings emphasize that LLMs are proficient at mimicking reasoning structures but not necessarily reasoning in a human-like, cognitive sense. The introduction of FRANKLIN offers a new means of evaluating these deficiencies, laying the groundwork for further research into improving LLM performance in multi-step question answering. The results underscore the need for continued refinement in how LLMs handle object-level reasoning, ensuring that future iterations can move beyond surface-level imitation and towards genuine cognitive reasoning abilities.
- Preliminary scientific report. Ferguson, N., Guillou, L., Bundy, A., & Nuamah, K. (2025). Evaluating the Meta- and Object-Level Reasoning of Large Language Models for Question Answering. ArXiv. https://arxiv.org/abs/2502.10338
News

A Simple Blood Test Could Predict Dementia Risk 25 Years Early
A single blood marker may quietly signal dementia risk decades in advance. Scientists at the University of California, San Diego, have identified a blood signal that could forecast dementia risk decades before symptoms begin. Their [...]
Sperm Get Lost in Space and Scientists Finally Know Why
Having a baby in space may be far more complicated than expected, as new research shows sperm struggle to find their way in microgravity. Starting a family beyond Earth could be more complicated than [...]
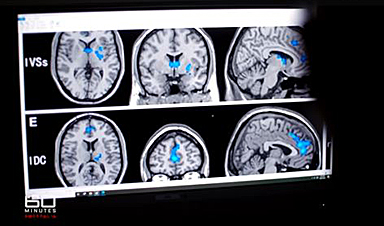
Digital Dementia – Brain fog and disassociation from being chronically online
New medical evidence, featured on 60 Minutes Australia, indicates excessive screen time is causing "digital dementia" in young Australians, with brain scans showing physical shrinkage and damage. Experts warn that high device usage (6-8 hours [...]
A new, highly mutated COVID variant called ‘Cicada’ is spreading in the US.
BA.3.2, a heavily mutated new COVID-19 variant which may be better able to escape immunity from vaccines or prior infection, is now spreading in the United States. Although COVID cases are currently low nationally, [...]

Molecular Manufacturing: The Future of Nanomedicine – New book from NanoappsMedical Inc.
This book explores the revolutionary potential of atomically precise manufacturing technologies to transform global healthcare, as well as practically every other sector across society. This forward-thinking volume examines how envisaged Factory@Home systems might enable the cost-effective [...]

Ancient bacteria strain discovered in ice cave is resistant to some modern antibiotics
In the depths of Scarisoara cave in Romania sits one of the world’s biggest underground glaciers, a monumental slab of ice the size of roughly 40 Olympic swimming pools that began to form around [...]

Scientists Identify “Good” Bacteria That May Prevent Long COVID
According to the WHO, about 6% of people worldwide who get COVID-19, roughly 400 million people, later develop a long-lasting form of the illness. That shows the condition remains a significant public health challenge. In [...]

New book from Nanoappsmedical Inc. – Global Health Care Equivalency
A new book by Frank Boehm, NanoappsMedical Inc. Founder. This groundbreaking volume explores the vision of a Global Health Care Equivalency (GHCE) system powered by artificial intelligence and quantum computing technologies, operating on secure [...]
RNA Recycling Extends Lifespan
Summary: Researchers discovered a biological “trash disposal” mechanism that directly controls how fast we age. While circular RNA has long been known to accumulate in cells as we get older, this study proves for the [...]
Cancer’s Deadly Paradox: How Tumors Break Their Own DNA To Keep Growing
Cancer’s strongest gene switches push DNA into damaging overdrive, creating repeated breaks and repairs that may fuel tumor evolution while exposing possible therapeutic weak spots. A new study indicates that cancer can harm its own genetic [...]

NanoMedical Brain/Cloud Interface – Explorations and Implications. A new book from Frank Boehm
New book from Frank Boehm, NanoappsMedical Inc Founder: This book explores the future hypothetical possibility that the cerebral cortex of the human brain might be seamlessly, safely, and securely connected with the Cloud via [...]

Our books now available worldwide!
Online Sellers other than Amazon, Routledge, and IOPP Indigo Global Health Care Equivalency in the Age of Nanotechnology, Nanomedicine and Artifcial Intelligence Global Health Care Equivalency In The Age Of Nanotechnology, Nanomedicine And Artificial [...]

Ryugu asteroid samples contain all DNA and RNA building blocks, bolstering origin-of-life theories
All the essential ingredients to make the DNA and RNA underpinning life on Earth have been discovered in samples collected from the asteroid Ryugu, scientists said Monday. The discovery comes after these building blocks [...]

Is Berberine Really a “Natural Ozempic”?
Often labeled a “natural Ozempic,” berberine is widely discussed as a metabolic aid. Yet research suggests its influence may lie deeper. In recent years, berberine has gained significant attention as a supposed “natural way” [...]
Viagra Ingredient Shows Promise for Rare Childhood Brain Disease in Surprising Study
A rare childhood disease with no approved treatment may have an unexpected new therapeutic candidate. Sildenafil, the active ingredient also sold under the brand name Viagra, may help reduce symptoms in people with Leigh [...]

In a first for China, Neuracle’s implantable brain-computer interface wins approval
In a landmark development, Neuracle Medical Technology has secured the country’s first-ever approval for an implantable brain-computer interface (BCI) system designed to restore hand motor function in patients with spinal cord injuries, in a [...]